今日内容:
一、垃圾回收机制
在计算机中,不能被程序访问到的数,称之为垃圾
1.1 引用计数
引用计数用来记录值的内存地址被记录的次数每引用一次就对标记 +1 操作每释放一次就对标记 -1 操作当内存中的值的引用计数为 0 时,该值就会被系统的垃圾回收机制回收
1.2 引用计数的问题
# 例子ls1 = [666]ls2 = [888]ls1.append(ls2)ls2.append(ls1)打印结果:[666, [888, [...]]][888, [666, [...]]]# 首先该语句不会执行错误,但是不会一直执行下去,# python解释器会对结果进行处理# ps:内存中,赋值操作只是将值的内存地址给拷贝给了变量名# 通过查找内存地址指向的内容将值找出来。
1.3 标记删除
标记: 标记的过程其实就是,遍历所有的GCRoots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,存放到新的内存空间中删除: 删除的过程将遍历堆中所有的对象,将之前所有的内容全部清除
1.4 分代回收
分代:指的是根据存活时间来为变量划分不同等级(也就是不同的代) 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次, 如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一, 当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长), 假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了, 节省了扫描的总时间,接下来,青春代中的对象, 也会以同样的方式被移动到老年代中。 也就是等级(代)越高,被垃圾回收机制扫描的频率越低回收:依然是使用引用计数作为回收的依据
2.正则表达式
2.1 什么是正则
正则就是带语法的字符串,用来匹配目标字符串得到想要的字符串结果
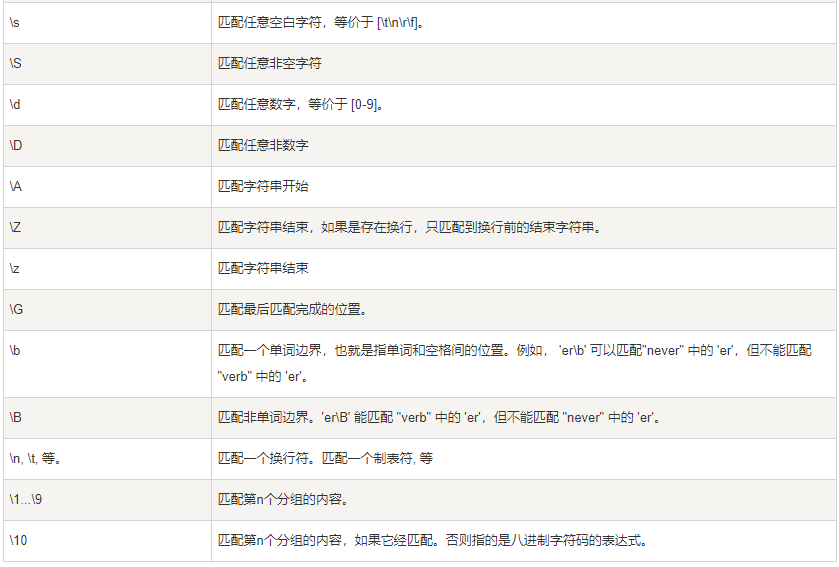
2.2 语法:
1.单个字符\d == [0-9]\D == [^0-9]\w == 字母+数字+_[0-9A-Za-z] == 所有字母+数字. == 匹配所有单个字符(刨除换行)
import restr1 = 'sfio29ia77y12飞范7发哦'# 匹配单个字符print(re.findall(r'a', str1))# ['a']# 匹配数字 == '\d'print(re.findall(r'[0-9]', str1))# ['2', '9', '7', '7', '1', '2', '7']# 匹配非数字 效果等同于 '\D'print(re.findall(r'[^0-9]', str1))# ['s', 'f', 'i', 'o', 'i', 'a', 'y', '飞', '范', '发', '哦']print(re.findall(r'\D', str1))# ['s', 'f', 'i', 'o', 'i', 'a', 'y', '飞', '范', '发', '哦']# 匹配字母+数字+_print(re.findall(r'\w', str1))# ['s', 'f', 'i', 'o', '2', '9', 'i', 'a', '7', '7', 'y', '1', '2', '飞', '范', '7', '发', '哦']# 匹配所有字母+数字print(re.findall(r'[0-9A-Za-z]', str1))# ['s', 'f', 'i', 'o', '2', '9', 'i', 'a', '7', '7', 'y', '1', '2', '7']# 匹配所有单个字符(刨除换行)print(re.findall(r'.', str1))# ['s', 'f', 'i', 'o', '2', '9', 'i', 'a', '7', '7', 'y', '1', '2', '飞', '范', '7', '发', '哦']
# 2.多个字符# zo* == zo{0,}# zo+ == zo{1,}# zo? == zo{0,1}import restr2 = 'sfizzjioa201jiszzzzzji45fzzja545ijf'# 匹配多个zzprint(re.findall(r'zz*', str2))print(re.findall(r'zz{0,}', str2))# ['zz', 'zzzzz', 'zz']# ['zz', 'zzzzz', 'zz']# 匹配一次或多次zzprint(re.findall(r'zz+', str2))print(re.findall(r'zz{1,}', str2))# ['zz', 'zzzzz', 'zz']# ['zz', 'zzzzz', 'zz']# 匹配0个或多个zzprint(re.findall(r'zz?', str2))print(re.findall(r'zz{0,1}', str2))# ['zz', 'zz', 'zz', 'z', 'zz']# ['zz', 'zz', 'zz', 'z', 'zz'] # 3.多行# ^: 以什么开头 $: 以什么结尾,结合 flags=re.M 可以按\n来完成多行匹配# re.S:将\n也能被.匹配 re.I:不区分大小写""""""import restr3 = 'zhangsJIansHUfhn54\nlisi'# ^ 以什么开头print(re.findall("^zhang", str3, flags=re.M))# ['zhang'] # 4.分组# 1.从左往右数数 ( 进行编号,自己的分组从1开始,group(0)代表匹配到的目标整体# 2.(?: ... ):取消所属分组,()就是普通(),可以将里面的信息作为整体包裹,但不产生分组
import reregexp = re.compile('(?:(http://)(.+)/)') # 生成正则对象target = regexp.match('http://www.baidu.com/')print(target.group(2)) # www.baidu.com# 5.拆分print(re.split('\s', '12ssw 456\n789\t000'))# ['12ssw', '456', '789', '000'] # 6.替换# 1.不参与匹配的原样带下# 2.参与匹配的都会被替换为指定字符串# 3.在指定字符串值\num拿到具体分组# 4.其他字符串信息都是原样字符串
print(re.sub('([a-z]+)(\d+)(.{2})', r'\2\1', '《abc123你好》'))# 《123abc》